業務でビジュアルリグレッション テストの導入を進めており、画像の比較と差分出力のツールとしてNode.jsで動くreg-suit を使用することになりました。
reg-suitではGitのコミットを辿り、どのコミットを比較対象にするか選択することができる「reg-keygen-git-hash-plugin 」というプラグイン があり、これを使用することでブランチをマージする前などに作業ブランチとその親ブランチの変更点をスクリーンショット で比較をすることができます。
このプラグイン でどのようにNode.jsでGitのブランチやコミットの情報を取得し、利用しているのか気になったのでプラグイン のコードを見てみました。
reg-keygen-git-hash-plugin
比較するスクリーンショット を識別するキーとしてGitのコミットハッシュを識別するために使われるプラグイン 。
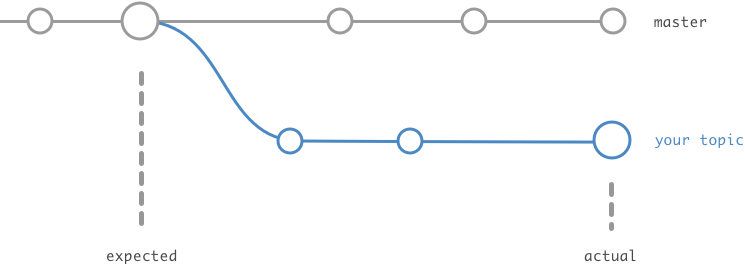
どのように比較するかは公式のREADME内で提示されているグラフを見るとわかりやすいです。
引用:https://github.com/reg-viz/reg-suit/blob/master/packages/reg-keygen-git-hash-plugin/README.md
コードを見ていく
srcの中のファイルは以下の3つ。
index.ts
まずはindex.tsから見ていきます。
import { KeyGeneratorPlugin, PluginCreateOptions, KeyGeneratorPluginFactory } from "reg-suit-interface" ;
import { fsUtil } from "reg-suit-util" ;
import { CommitExplorer } from "./commit-explorer" ;
class GitHashKeyGenPlugin implements KeyGeneratorPlugin {
init( config: PluginCreateOptions) : void {
this ._conf = config;
}
getExpectedKey() : Promise< string > {
}
getActualKey() : Promise< string > {
}
}
const pluginFactory: KeyGeneratorPluginFactory = () => {
return {
keyGenerator: new GitHashKeyGenPlugin(),
} ;
} ;
export = pluginFactory;
index.tsにはGitHashKeyGenPluginクラスが定義されています。getExpectedKeyとgetActuralKeyが重要そうで、メソッドの名前から比較元と比較先のキーとしてGitのコミットハッシュを取得をするメソッドだと予測できます。getExpectedKeyの中は以下のようになっています。
class GitHashKeyGenPlugin implements KeyGeneratorPlugin {
getExpectedKey() : Promise< string > {
if ( !this ._checkAndMessage()) {
return Promise.reject< string >( null );
}
try {
const result = this ._explorer.getBaseCommitHash();
if ( result) {
return Promise.resolve( result);
} else {
return Promise.reject< string >( null );
}
} catch ( e) {
this ._conf.logger.error( this ._conf.logger.colors.red( e.message));
return Promise.reject< string >( null );
}
}
...
}
_checkAndMessage()はgitの情報を取得できるか判断するために.gitディレクト リが作業ディレクト リ内に存在するかをチェックするメソッド。
Git操作可能であれば別ファイルから読み込んだCommitExplorerクラスのインスタンス からgetBaseCommitHashメソッドを呼び出して、比較元のコミットハッシュを取得しています。
getActualKeyメソッドの処理も同じようにCommitExplorerのインスタンス からgetCurrentCommitHashメソッドを呼び出して比較先のコミットハッシュを取得しています。
次にCommitExplorerの詳細を見ていきます。
GitCmdClientクラスで取得したコミット情報を利用して比較対象のコミットを探すための処理がまとめられています。
見ていくコード量が多かったので、コード内に直接メモを書いています。
また、複雑で理解しきれていないくてメモできていない部分や間違ったことを書いている可能性がありますのでご了承ください。
import { GitCmdClient } from "./git-cmd-client" ;
export type CommitNode = string [] ;
export class CommitExplorer {
private _gitCmdClient = new GitCmdClient();
private _commitNodes!: CommitNode[] ;
private _branchName!: string ;
private _branchNameCache: { [ hash: string ] : string [] } = {} ;
getCommitNodes() : CommitNode[] {
return this ._gitCmdClient
.logGraph()
.split( " \n " )
.map(( hashes: string ) =>
hashes
.replace( /\*|\/|\||\\|_|-+\.|/g , "" )
.split( " " )
.filter( hash => !!hash),
)
.filter(( hashes: CommitNode) => hashes.length );
}
getCurrentBranchName() : string {
const currentName = this ._gitCmdClient.currentName() .replace( " \n " , "" );
if (
currentName.startsWith( "(HEAD detached" ) ||
currentName.startsWith( "(no branch" ) ||
currentName.startsWith( "(detached from" ) ||
( currentName.startsWith( "[" ) && currentName.indexOf( "detached" ) !== -1 )
) {
throw new Error ( "Can't detect branch name because HEAD is on detached commit node." );
}
return currentName;
}
getCurrentCommitHash() : string {
const currentName = this ._branchName;
if ( !currentName || !currentName.length ) {
throw new Error ( "Fail to detect the current branch." );
}
return this ._gitCmdClient.revParse( currentName) .replace( " \n " , "" );
}
getBranchNames( hash: string ) : string [] {
if ( this ._branchNameCache[ hash] ) return this ._branchNameCache[ hash] ;
const names = this ._gitCmdClient
.containedBranches( hash)
.split( " \n " )
.filter( h => !!h)
.map( branch => branch.replace( "*" , "" ) .trim());
this ._branchNameCache[ hash] = names;
return names;
}
getAllBranchNames() : string [] {
return this ._gitCmdClient
.branches()
.split( " \n " )
.map( b => b.replace( /^\*/ , "" ) .trim() .split( " " ) [ 0 ] )
.filter( b => !!b || b === this ._branchName)
.filter(( x, i, self ) => self .indexOf( x) === i);
}
getIntersection( hash: string ) : string | undefined {
try {
return this ._gitCmdClient.mergeBase( hash, this ._branchName) .slice( 0 , 8 );
} catch ( e) {}
}
getBranchHash() : string | undefined {
const branches = this .getAllBranchNames();
return branches
.map( b => {
const hash = this .getIntersection( b);
const time = hash ? new Date ( this ._gitCmdClient.logTime( hash) .trim()) .getTime() : Number .MAX_SAFE_INTEGER;
return { hash, time } ;
} )
.filter( a => !!a.hash)
.sort(( a, b) => a.time - b.time)
.map( b => b.hash) [ 0 ] ;
}
getCandidateHashes() : string [] {
const mergedBranches = this .getBranchNames( this ._commitNodes[ 0 ][ 0 ] ) .filter(
b => !b.endsWith( "/" + this ._branchName) && b !== this ._branchName,
);
return this ._commitNodes
.map( c => c[ 0 ] )
.filter( c => {
const branches = this .getBranchNames( c);
const hasCurrent = !!branches.find( b => this ._branchName === b);
const others = branches.filter( b => {
return !( b.endsWith( this ._branchName) || ( mergedBranches.length && mergedBranches.some( c => b === c)));
} );
return hasCurrent && !!others.length ;
} );
}
isReachable( a: string , b: string ) {
const between = this ._gitCmdClient.logBetween( a, b) .trim();
return !between;
}
findBaseCommitHash( candidateHashes: string [] , branchHash: string ) : string | undefined {
const traverseLog = ( candidateHash: string ) : boolean | undefined => {
if ( candidateHash === branchHash) return true ;
return this .isReachable( candidateHash, branchHash);
} ;
const target = candidateHashes.find( hash => !!traverseLog( hash));
return target;
}
getBaseCommitHash() : string | null {
this ._branchName = this .getCurrentBranchName();
this ._commitNodes = this .getCommitNodes();
const candidateHashes = this .getCandidateHashes();
const branchHash = this .getBranchHash();
if ( !branchHash) return null ;
const baseHash = this .findBaseCommitHash( candidateHashes, branchHash);
if ( !baseHash) return null ;
const result = this ._gitCmdClient.revParse( baseHash) .replace( " \n " , "" );
return result ? result : null ;
}
}
git-cmd-client.ts
最後にGitCmdClientクラスのコードを見ていきます。
Gitのコマンドを直接呼び出す処理がまとめられています。
コード概要
import { execSync } from "child_process" ;
import shellEscape from "shell-escape" ;
export class GitCmdClient {
private _revParseHash: { [ key: string ] : string } = {} ;
currentName() {
return execSync( 'git branch | grep "^ \\ *" | cut -b 3-' , { encoding: "utf8" } );
}
revParse( currentName: string ) {
if ( !this ._revParseHash[ currentName] ) {
this ._revParseHash[ currentName] = execSync( `git rev-parse "${currentName}"` , { encoding: "utf8" } );
}
return this ._revParseHash[ currentName] ;
}
branches() {
return execSync( "git branch -a" , { encoding: "utf8" } );
}
containedBranches( hash: string ) : string {
return execSync( shellEscape( [ "git" , "branch" , "-a" , "--contains" , hash] ), { encoding: "utf8" } );
}
logTime( hash: string ) {
return execSync( shellEscape( [ "git" , "log" , "--pretty=%ci" , "-n" , "1" , hash] ), { encoding: "utf8" } );
}
logBetween( a: string , b: string ) {
return execSync( shellEscape( [ "git" , "log" , "--oneline" , `${a}..${b}` ] ), { encoding: "utf8" } );
}
logGraph() {
return execSync( 'git log -n 300 --graph --pretty=format:"%h %p"' , { encoding: "utf8" } );
}
mergeBase( a: string , b: string ) {
return execSync( shellEscape( [ "git" , "merge-base" , "-a" , a, b] ), { encoding: "utf8" } );
}
}
使用しているモジュール
Node.js child_process
https://nodejs.org/api/child_process.html#child_process_child_process
The child_process module provides the ability to spawn subprocesses in a manner that is similar, but not identical, to popen(3). This capability is primarily provided by the child_process.spawn() function:
サブプロセスを生成する機能を提供するモジュール。
child_process.execSync()
The child_process.execSync() method is generally identical to child_process.exec() with the exception that the method will not return until the child process has fully closed. When a timeout has been encountered and killSignal is sent, the method won't return until the process has completely exited. If the child process intercepts and handles the SIGTERM signal and doesn't exit, the parent process will wait until the child process has exited.
execメソッドを非同期ではなく同期処理で呼び出すメソッド。
Node.jsのメソッドは基本的に非同期処理されるので、同期処理をしたい場合はメソッド名の後ろにSyncとついたメソッドが用意されていることが多い。
child_process.exec()
https://nodejs.org/api/child_process.html#child_process_child_process_exec_command_options_callback
Spawns a shell then executes the command within that shell, buffering any generated output. The command string passed to the exec function is processed directly by the shell and special characters (vary based on shell) need to be dealt with accordingly
シェルを生成し、そのシェル内でコマンドを実行して、生成された出力をバッファリングする。
shell-escape
https://github.com/xxorax/node-shell-escape エス ケープする
// 実行例
var shellescape = require('shell-escape');
var args = ['curl', '-v', '-H', 'Location;', '-H', 'User-Agent: dave#10', 'http://www.daveeddy.com/?name=dave&age=24'];
var escaped = shellescape(args);
console.log(escaped);
//出力結果
curl -v -H 'Location;' -H 'User-Agent: dave#10' 'http://www.daveeddy.com/?name=dave&age=24'
まとめ
コードを見てなんとなく全体像を掴めました。
Nodejsでのコマンドの実行にchild_processモジュールとshell-escapeもモジュールが使われていることがわかったので、今後コマンドライン ツールを作るときに活用できそうです。
また、Gitコマンドを直接呼び出すクラスとコミット情報を加工するクラスを分けるといったクラス設計の考え方も具体的な実装から学ぶことができました。